


Machine Learning Confronts the Elephant in the Room
|
Getting your Trinity Audio player ready...
|
Score one for the human brain. In a new study, computer scientists found that artificial intelligence systems fail a vision test a child could accomplish with ease.
“It’s a clever and important study that reminds us that ‘deep learning’ isn’t really that deep,” said Gary Marcus, a neuroscientist at New York University who was not affiliated with the work.
The result takes place in the field of computer vision, where artificial intelligence systems attempt to detect and categorize objects. They might try to find all the pedestrians in a street scene, or just distinguish a bird from a bicycle (which is a notoriously difficult task). The stakes are high: As computers take over critical tasks like automated surveillance and autonomous driving, we’ll want their visual processing to be at least as good as the human eyes they’re replacing.
It won’t be easy. The new work accentuates the sophistication of human vision — and the challenge of building systems that mimic it. In the study, the researchers presented a computer vision system with a living room scene. The system processed it well. It correctly identified a chair, a person, books on a shelf. Then the researchers introduced an anomalous object into the scene — an image of an elephant. The elephant’s mere presence caused the system to forget itself: Suddenly it started calling a chair a couch and the elephant a chair, while turning completely blind to other objects it had previously seen.
“There are all sorts of weird things happening that show how brittle current object detection systems are,” said Amir Rosenfeld, a researcher at York University in Toronto and co-author of the study along with his York colleague John Tsotsos and Richard Zemel of the University of Toronto.
Researchers are still trying to understand exactly why computer vision systems get tripped up so easily, but they have a good guess. It has to do with an ability humans have that AI lacks: the ability to understand when a scene is confusing and thus go back for a second glance.
The Elephant in the Room
Eyes wide open, we take in staggering amounts of visual information. The human brain processes it in stride. “We open our eyes and everything happens,” said Tsotsos.
Artificial intelligence, by contrast, creates visual impressions laboriously, as if it were reading a description in Braille. It runs its algorithmic fingertips over pixels, which it shapes into increasingly complex representations. The specific type of AI system that performs this process is called a neural network. It sends an image through a series of “layers.” At each layer, the details of the image — the colors and brightnesses of individual pixels — give way to increasingly abstracted descriptions of what the image portrays. At the end of the process, the neural network produces a best-guess prediction about what it’s looking at.
“It’s all moving from one layer to the next by taking the output of the previous layer, processing it and passing it along to the next layer, like a pipeline,” said Tsotsos.
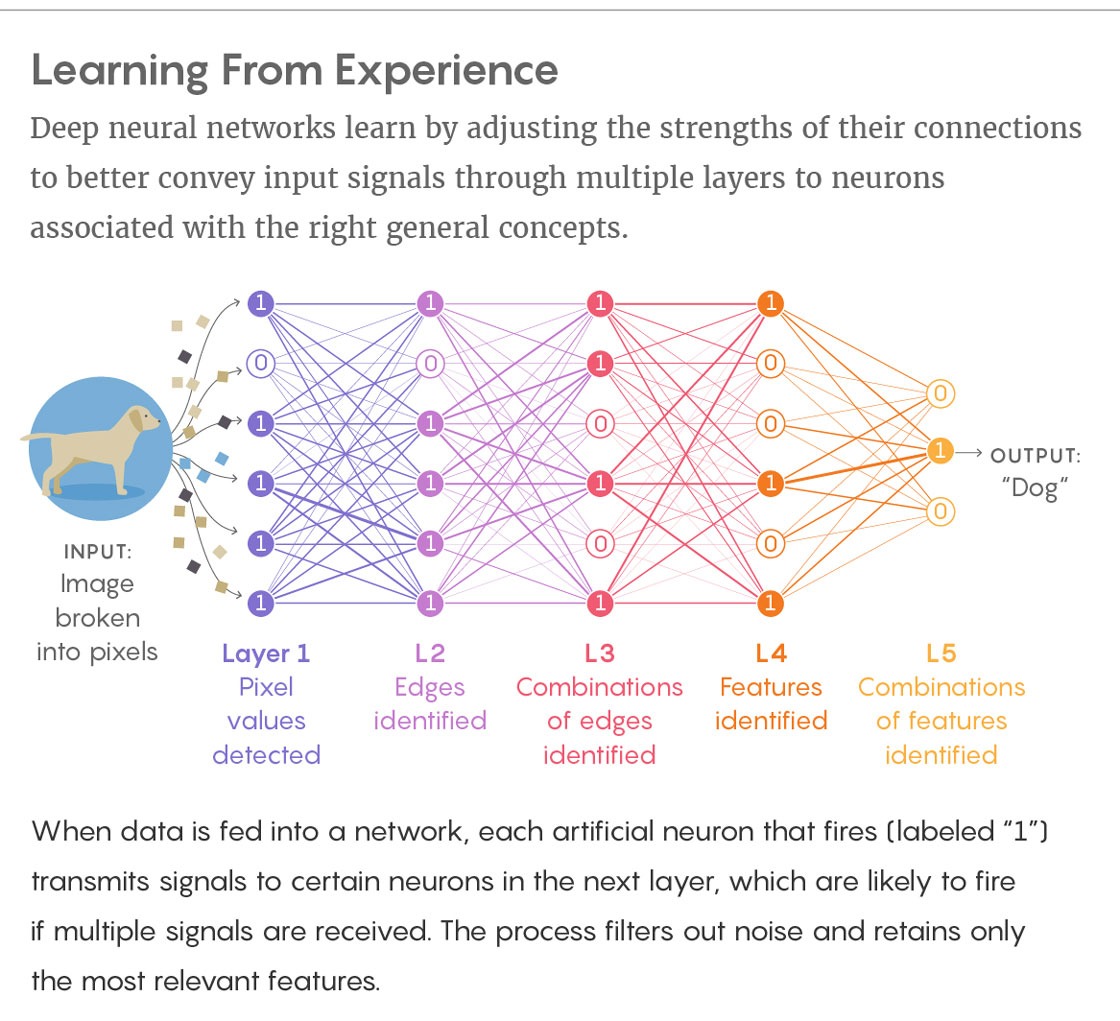
Deep neural networks learn by adjusting the strengths of their connections to better convey input signals through multiple layers to neurons associated with the right general concepts. When data is fed into a network, each artificial neuron that fires (labeled “1”) transmits signals to certain neurons in the next layer, which are likely to fire if multiple signals are received. The process filters out noise and retains only the most relevant features.
Neural networks are adept at specific visual chores. They can outperform humans in narrow tasks like sorting objects into best-fit categories — labeling dogs with their breed, for example. These successes have raised expectations that computer vision systems might soon be good enough to steer a car through crowded city streets.
They’ve also provoked researchers to probe their vulnerabilities. In recent years there have been a slew of attempts, known as “adversarial attacks,” in which researchers contrive scenes to make neural networks fail. In one experiment, computer scientists tricked a neural network into mistaking a turtle for a rifle. In another, researchers waylaid a neural network by placing an image of a psychedelically colored toaster alongside ordinary objects like a banana.
This new study has the same spirit. The three researchers fed a neural network a living room scene: A man seated on the edge of a shabby chair leans forward as he plays a video game. After chewing on this scene, a neural network correctly detected a number of objects with high confidence: a person, a couch, a television, a chair, some books.

Then the researchers introduced something incongruous into the scene: an image of an elephant in semiprofile. The neural network started getting its pixels crossed. In some trials, the elephant led the neural network to misidentify the chair as a couch. In others, the system overlooked objects, like a row of books, that it had correctly detected in earlier trials. These errors occurred even when the elephant was far from the mistaken objects.
Snafus like those extrapolate in unsettling ways to autonomous driving. A computer can’t drive a car if it might go blind to a pedestrian just because a second earlier it passed a turkey on the side of the road.
And as for the elephant itself, the neural network was all over the place: Sometimes the system identified it correctly, sometimes it called the elephant a sheep, and sometimes it overlooked the elephant completely.
“If there is actually an elephant in the room, you as a human would likely notice it,” said Rosenfeld. “The system didn’t even detect its presence.”
Everything Connected to Everything
When human beings see something unexpected, we do a double take. It’s a common phrase with real cognitive implications — and it explains why neural networks fail when scenes get weird.
Today’s best neural networks for object detection work in a “feed forward” manner. This means that information flows through them in only one direction. They start with an input of fine-grained pixels, then move to curves, shapes, and scenes, with the network making its best guess about what it’s seeing at each step along the way. As a consequence, errant observations early in the process end up contaminating the end of the process, when the neural network pools together everything it thinks it knows in order to make a guess about what it’s looking at.
Photo of Amir Rosenfeld
Amir Rosenfeld, a researcher at York University in Toronto, said that the new work shows “how brittle current object detection systems are.”
Courtesy of Amir Rosenfeld
“By the top of the neural network you have everything connected to everything, so you have the potential to have every feature in every location interfering with every possible output,” said Tsotsos.
The human way is better. Imagine you’re given a very brief glimpse of an image containing a circle and a square, with one of them colored blue and the other red. Afterward you’re asked to name the color of the square. With only a single glance to go on, you’re likely to confuse the colors of the two shapes. But you’re also likely to recognize that you’re confused and to ask for another look. And, critically, when you take that second look, you know to focus your attention on just the color of the square.
“The human visual system says, ‘I don’t have right answer yet, so I have to go backwards to see where I might have made an error,’” explained Tsotsos, who has been developing a theory called selective tuning that explains this feature of visual cognition.
Most neural networks lack this ability to go backward. It’s a hard trait to engineer. One advantage of feed-forward networks is that they’re relatively straightforward to train — process an image through these six layers and get an answer. But if neural networks are to have license to do a double take, they’ll need a sophisticated understanding of when to draw on this new capacity (when to look twice) and when to plow ahead in a feed-forward way. Human brains switch between these different processes seamlessly; neural networks will need a new theoretical framework before they can do the same.
Source: Quantamagazine